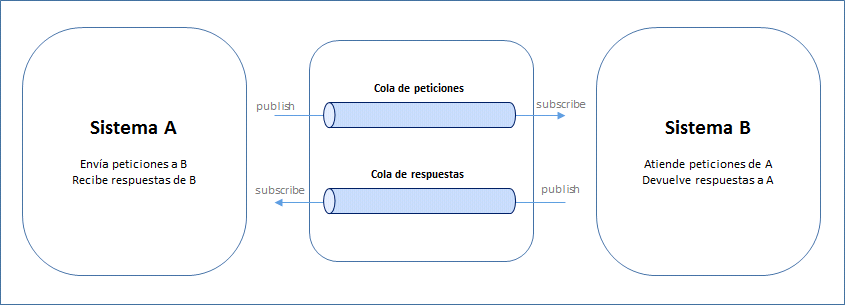
Arquitectura híbrida cloud / on-premise
La capa gratuita de Amazon web services ofrece una
instancia mínima de cómputo EC2 en la nube sin coste durante 12 meses. Se
trata de una instancia t2.micro (1 vCPU, 1 GB RAM) y hasta 30 GB de
almacenamiento en volúmenes Amazon EBS (Elastic Block
Store).
Aun tratándose de una máquina con capacidades
limitadas, nos ofrece una disponibilidad 24/7 y toda la flexibilidad de un
IaaS, por lo que se le puede dar un uso de provecho, aunque sea para hacer pequeños experimentos.
Así que he optado por rescatar una máquina virtual
donde había hecho algunos experimentos con Elastic stack y la he
complementado con la instancia AWS mencionada para montar una solución híbrida
cloud / on-premise para la ingesta 24/7 de eventos online
(en concreto, tweets) y su posterior explotación on-premise con ELK:

En el lado del cloud corre un Logtash escuchando Twitter con ayuda del plugin correspondiente. Está configurado para capturar nuevos tweets de algunas cuentas concretas, o que contengan determinadas palabras. Más info sobre captura y análisis de tweets con ELK aquí y aquí.
Me he apoyado en Apache Kafka funcionando como cola de mensajes para almacenarlos temporalmente en AWS hasta su descarga (patrón productor-consumidor).
Por último, en la máquina virtual local corre un stack ELK simple, formado por un Logstash, que se conecta a Kafka para descargar los eventos allí almacenados, un Elasticsearch para la indexación y almacenamiento de los tweets, y un Kibana para la explotación visual de esta información:

Me he apoyado en Apache Kafka funcionando como cola de mensajes para almacenarlos temporalmente en AWS hasta su descarga (patrón productor-consumidor).
Por último, en la máquina virtual local corre un stack ELK simple, formado por un Logstash, que se conecta a Kafka para descargar los eventos allí almacenados, un Elasticsearch para la indexación y almacenamiento de los tweets, y un Kibana para la explotación visual de esta información:

De esta forma, por un lado se aprovecha la instancia en la nube siempre encendida, y por otro la mayor capacidad de procesamiento de una máquina virtual corriendo on-premise, sin mantenerla permanentemente en funcionamiento.
En cuanto a la operativa habitual, Kafka está configurado (de momento) con una retención de eventos de hasta 8 días (una semana entera, más el día en curso) y puede llenar hasta 10 GB de espacio en disco (aprox. el 50% del disco disponible).
Para la explotación de datos se arranca la MV en local, se inician Elasticsearch y Kibana, y por último, se levanta el proceso Logstash, que se conectará a AWS para proceder a la descarga de los eventos allí recopilados desde la última conexión, como muestra (de una forma un poco cutre) este vídeo:
Quedan aún pendientes de resolver algunos temas, como la seguridad (p. ej. cifrando el tráfico entre ambas máquinas) pero de momento nos sirve para cacharrear, que es de lo que se trata.
Hasta otra.
En cuanto a la operativa habitual, Kafka está configurado (de momento) con una retención de eventos de hasta 8 días (una semana entera, más el día en curso) y puede llenar hasta 10 GB de espacio en disco (aprox. el 50% del disco disponible).
Para la explotación de datos se arranca la MV en local, se inician Elasticsearch y Kibana, y por último, se levanta el proceso Logstash, que se conectará a AWS para proceder a la descarga de los eventos allí recopilados desde la última conexión, como muestra (de una forma un poco cutre) este vídeo:
Quedan aún pendientes de resolver algunos temas, como la seguridad (p. ej. cifrando el tráfico entre ambas máquinas) pero de momento nos sirve para cacharrear, que es de lo que se trata.
Hasta otra.
Comentarios
Publicar un comentario