Desacoplamiento mediante colas de mensajes
En esta entrada vamos a diseñar un sistema en el que algunos componentes interactúan de forma desacoplada mediante el uso de colas de mensajes, con el fin de mejorar el rendimiento, la tolerancia a fallos y la escalabilidad.
La necesidad surgió a la hora de redactar una propuesta para sustituir a un sistema anterior que se estaba quedando obsoleto, en la que se incluiría el diseño a alto nivel de un nuevo sistema pensado para solventar las limitaciones del anterior, especialmente en lo relativo a escalabilidad.
Realmente desconozco el estado actual del asunto, pues me llegó como una conversación de pasillo. Casi no había requisitos y tuve que inventármelos, pero básicamente el sistema debía consistir en lo siguiente:
Se trata de una aplicación o funcionalidad web, a disposición de los ciudadanos en Internet, para la consulta de información agregada (expedientes, notificaciones...) procedente de diferentes organismos de la Administración integrados con el sistema. Es decir, una especie de punto de acceso único para la consulta en múltiples sistemas y almacenes de información remotos de las diferentes administraciones.
Según me comentaron, el sistema anterior básicamente consistía en una aplicación web donde el usuario, una vez iniciada la sesión, podía realizar diferentes consultas. En el corazón del sistema, un ESB era el encargado de ir llamando 'lo más en paralelo posible' a los diferentes backends o servicios web de cada organismo, para componer posteriormente la respuesta con toda la información agregada. Con 'lo más en paralelo posible' quiero decir que el ESB iba llamando de forma síncrona a los diferentes webservices en pequeños lotes, de forma iterativa/secuencial, por lo que la latencia tras cada lote se iba acumulando especialmente a medida que éstos iban creciendo en número. Además, en un pico de demanda la alta concurrencia podría dejar tieso el invento.
De nuevo según me comentaron, inicialmente existían unas pocas decenas de servicios a los que invocar, poco a poco el número fue creciendo hasta casi duplicarse, y los problemas de latencia empezaron a ser importantes. Y al parecer estaba previsto que este número fuera a dispararse a corto plazo, y no resultaba trivial hacer escalar el sistema añadiendo más máquinas, de ahí la necesidad de repensar algunas cosas.
Aquí es precisamente donde parece una buena idea desacoplar por diseño el nuevo sistema de todos esos servicios de terceros a los que deberá invocar, y eso podemos solucionarlo utilizando colas de mensajes entre el core del sistema y los conectores, clientes multi-hilo encargados de invocar a los backends a medida que les llegan estos mensajes de petición y a continuación encolar las respuestas obtenidas.
Adicionalmente, usar un enfoque orientado a microservicios para construir los componentes (frontal, core, conectores) y utilizar herramientas diseñadas con la escalabilidad en mente (p. ej. Apache Kafka para mensajería) ayudarán a hacer crecer la capacidad del sistema cuando sea necesario.
Pero antes de entrar en faena vamos a hablar un poco de las colas de mensajes.
COLAS DE MENSAJES
Dos o más sistemas pueden comunicarse de forma asíncrona mediante colas de mensajes, siguiendo el patrón publish-subscribe: los sistemas que generan y envían los mensajes (publicadores / productores) los dejan en una cola, de la que posteriormente serán obtenidos por los sistemas a los que van dirigidos (suscriptores / consumidores).
A diferencia de un modelo de comunicación síncrono, en el que un sistema envía un mensaje a otro directamente, no es necesario que publicadores y suscriptores funcionen a la vez ni a la misma velocidad, sino que los suscriptores irán consumiendo y procesando los mensajes de la cola a su ritmo y por lo general en orden (estructura FIFO), lo que ayuda a descongestionar el sistema y minimizar los errores ante un pico de carga, y permite detener temporalmente alguno de estos sistemas sin interrumpir la actividad del resto.
Básicamente es como cuando contactamos con alguien por whatsapp o email en lugar de llamarle por teléfono: ‘ya lo leerá cuando pueda’.
Es posible modelar una interacción petición-respuesta entre dos sistemas A y B de forma asíncrona colocando un par de colas (comunicación bidireccional) entre ellos:
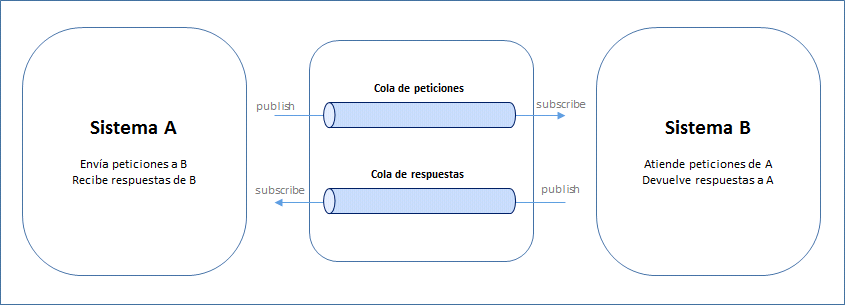
Y eso es lo que haremos en nuestro sistema para desacoplarlo de los servicios de terceros a los que debe invocar. Puesto que dichos servicios deben ser invocados de forma síncrona (vía HTTP SOAP o REST, o incluso TCP) construiremos una capa de conectores encargada de las invocaciones (patrón facade) que funcionará como suscriptor. Lo veremos en detalle más adelante.
Píldoras recomendadas:
REQUISITOS (CASI) INVENTADOS
Volvamos al asunto. Como requisitos funcionales básicos tenemos:
¡Llega el momento de pizarra y rotuladores de colores!
ARQUITECTURA LÓGICA
La arquitectura lógica del sistema es la siguiente:

A continuación detallaremos cada uno de los elementos que la componen:
La solución de mensajería para la integración asíncrona de componentes estará basada en Apache Kafka.
La solución de persistencia temporal para la gestión de solicitudes de usuario y cacheado de respuestas parciales por parte del componente hub estará basada en Apache Cassandra.
El frontal web será un aplicativo basado en Spring Web MVC, apoyándose en diferentes frameworks y tecnologías de presentación (p. ej. Angular, JQuery, AJAX, JSRS), pudiendo así ofrecer diferentes interfaces a diferentes navegadores (retro-compatibilidad mediante patrones backend-for-frontend).
Los componentes batch estarán basados en Spring Batch.
CONECTORES
La capa de conectores la componen diferentes módulos, independientes entre sí, uno por cada backend existente con el que integrarse. Cada conector debe implementar la correspondiente llamada al backend de un organismo, mediante el protocolo que corresponda.
El objetivo de esta capa es abstraer a otros componentes de las peculiaridades del acceso a cada backend de forma independiente:
Esta configuración debería poder ser inyectada en tiempo de despliegue o ejecución apoyándonos para ello en el componente correspondiente de la arquitectura de microservicios destinado a tal efecto (p. ej. Archaius)
Implementación de los conectores
Los conectores funcionarán en modo ‘batch’, y en cada iteración se realizarán las siguientes tareas:
Los valores de timeout también serán configurables de forma independiente para cada conector, lo que permitirá afinar la configuración en función de las capacidades de carga de cada backend.
Podrán desplegarse múltiples instancias de cada conector, con el fin de aumentar la disponibilidad y tolerancia a fallos. En este caso, la concurrencia de invocaciones al backend vendrá determinada por el nº de instancias y el nº de threads de ejecución en paralelo de cada una de ellas.
La implementación de un patrón circuit-breaker configurable (p. ej. mediante Hystrix) permitirá ‘abrir el circuito’ temporalmente cuando se detecten múltiples errores consecutivos en el acceso a un determinado backend. Esto minimizará la carga del sistema y la propagación de errores, evitando peticiones masivas a un backend que presenta problemas en un momento puntual. Con el circuito ‘abierto’, el conector devolverá mensajes de KO indicando este motivo. Se deben definir y configurar los criterios de ‘apertura’ y ‘cierre del circuito’ en cada caso.
Integración con el componente message-broker (Kafka)
Como consumidor de mensajes de la cola de peticiones (subscriber) cada conector se considera un ‘consumer group’, y cada instancia individual de un conector es considerado un miembro de dicho grupo.
El message-broker mantiene un puntero (offset) para cada consumer-group, indicando el siguiente mensaje a entregar. De forma que cada conector, en función del número de instancias en ejecución, rendimiento de cada backend, etc., pueda avanzar a su ritmo de forma independiente (p. ej. backends con diferentes capacidades de carga, tiempos de respuesta heterogéneos, throughput irregular)
Esto garantiza lo siguiente:
MESSAGE-BROKER
El componente message-broker, basado en Apache Kafka, es una solución escalable que permite integrar de forma asíncrona el hub (que es quien contiene la lógica del sistema) con la capa de conectores mediante el intercambio bidireccional de mensajes, actuando además como medida de contención ante la congestión del sistema durante el acceso masivo a los backends.
Éste se basa en el patrón publish-subscribe, y está inicialmente compuesto por un par único de colas (estructura FIFO) compartidas por todos los conectores:
No obstante, si el número de conectores crece notablemente, se definirá un criterio de agrupamiento de los mismos y se definirá un par dedicado de colas petición-respuesta para cada grupo de conectores. Esto permitirá reducir en cada conector el posible overhead resultante de preprocesar (y descartar) todos los mensajes que no van dirigidos al mismo.
HUB (CONCENTRADOR)
El componente hub o concentrador es el principal componente del core del sistema y alberga toda la lógica de negocio y control del mismo. Principalmente es el responsable de:
Para cada solicitud entrante, en función de la lógica de negocio implementada enviará a la capa de conectores los correspondientes mensajes a través del message-broker (publisher en la cola de peticiones) para su procesamiento.
Cada módulo dispondrá de su correspondiente logger para volcar información de depuración que posibilite su monitorización y facilite la trazabilidad de eventos en el sistema y el diagnóstico de problemas.
FRONTAL WEB
Por último tenemos el frontal web. Se trata de una aplicación web basada en Spring Web MVC que constituye la capa de presentación del sistema. Sus responsabilidades básicas son las siguientes:
CONCLUSIONES
Como hemos visto, el uso de colas de mensajes permite desacoplar componentes del sistema y aprovechar las ventajas que ello conlleva. Esto no sale gratis, sino que introduce cierta complejidad y esfuerzo adicional que hay que abordar, pero para ciertos tipos de sistemas seguir este enfoque compensa con creces y permite dotarlos de una mayor robustez y tolerancia a fallos y picos de carga.
Una vez entregado este diseño no tuve más noticias al respecto, pero como tenía algo de tiempo disponible me propuse construir una pequeña prueba de concepto para comprobar qué tal podría llegar a funcionar. Y lo hice:


Pero eso os lo cuento otro día :)
La necesidad surgió a la hora de redactar una propuesta para sustituir a un sistema anterior que se estaba quedando obsoleto, en la que se incluiría el diseño a alto nivel de un nuevo sistema pensado para solventar las limitaciones del anterior, especialmente en lo relativo a escalabilidad.
Realmente desconozco el estado actual del asunto, pues me llegó como una conversación de pasillo. Casi no había requisitos y tuve que inventármelos, pero básicamente el sistema debía consistir en lo siguiente:
Se trata de una aplicación o funcionalidad web, a disposición de los ciudadanos en Internet, para la consulta de información agregada (expedientes, notificaciones...) procedente de diferentes organismos de la Administración integrados con el sistema. Es decir, una especie de punto de acceso único para la consulta en múltiples sistemas y almacenes de información remotos de las diferentes administraciones.
Según me comentaron, el sistema anterior básicamente consistía en una aplicación web donde el usuario, una vez iniciada la sesión, podía realizar diferentes consultas. En el corazón del sistema, un ESB era el encargado de ir llamando 'lo más en paralelo posible' a los diferentes backends o servicios web de cada organismo, para componer posteriormente la respuesta con toda la información agregada. Con 'lo más en paralelo posible' quiero decir que el ESB iba llamando de forma síncrona a los diferentes webservices en pequeños lotes, de forma iterativa/secuencial, por lo que la latencia tras cada lote se iba acumulando especialmente a medida que éstos iban creciendo en número. Además, en un pico de demanda la alta concurrencia podría dejar tieso el invento.
De nuevo según me comentaron, inicialmente existían unas pocas decenas de servicios a los que invocar, poco a poco el número fue creciendo hasta casi duplicarse, y los problemas de latencia empezaron a ser importantes. Y al parecer estaba previsto que este número fuera a dispararse a corto plazo, y no resultaba trivial hacer escalar el sistema añadiendo más máquinas, de ahí la necesidad de repensar algunas cosas.
Aquí es precisamente donde parece una buena idea desacoplar por diseño el nuevo sistema de todos esos servicios de terceros a los que deberá invocar, y eso podemos solucionarlo utilizando colas de mensajes entre el core del sistema y los conectores, clientes multi-hilo encargados de invocar a los backends a medida que les llegan estos mensajes de petición y a continuación encolar las respuestas obtenidas.
Adicionalmente, usar un enfoque orientado a microservicios para construir los componentes (frontal, core, conectores) y utilizar herramientas diseñadas con la escalabilidad en mente (p. ej. Apache Kafka para mensajería) ayudarán a hacer crecer la capacidad del sistema cuando sea necesario.
Pero antes de entrar en faena vamos a hablar un poco de las colas de mensajes.
COLAS DE MENSAJES
Dos o más sistemas pueden comunicarse de forma asíncrona mediante colas de mensajes, siguiendo el patrón publish-subscribe: los sistemas que generan y envían los mensajes (publicadores / productores) los dejan en una cola, de la que posteriormente serán obtenidos por los sistemas a los que van dirigidos (suscriptores / consumidores).
A diferencia de un modelo de comunicación síncrono, en el que un sistema envía un mensaje a otro directamente, no es necesario que publicadores y suscriptores funcionen a la vez ni a la misma velocidad, sino que los suscriptores irán consumiendo y procesando los mensajes de la cola a su ritmo y por lo general en orden (estructura FIFO), lo que ayuda a descongestionar el sistema y minimizar los errores ante un pico de carga, y permite detener temporalmente alguno de estos sistemas sin interrumpir la actividad del resto.
Básicamente es como cuando contactamos con alguien por whatsapp o email en lugar de llamarle por teléfono: ‘ya lo leerá cuando pueda’.
Es posible modelar una interacción petición-respuesta entre dos sistemas A y B de forma asíncrona colocando un par de colas (comunicación bidireccional) entre ellos:
- El sistema A envía peticiones al sistema B encolando mensajes en la cola de peticiones como publicador, y permanece a la espera escuchando en la cola de respuestas como suscriptor
- El sistema B permanece a la espera escuchando en la cola de peticiones como suscriptor, procesa cada mensaje recibido y encola la respuesta generada en la cola de respuestas como publicador
Píldoras recomendadas:
- https://blog.agetic.gob.bo/2017/09/desacoplamiento-desacoplamiento-desacoplamiento/
- https://enmilocalfunciona.io/aprendiendo-apache-kafka-parte-1/
REQUISITOS (CASI) INVENTADOS
Volvamos al asunto. Como requisitos funcionales básicos tenemos:
- Acceso al sistema vía web
- Identificación del usuario / control de acceso mediante diferentes mecanismos (usuario/contraseña, DNIe, etc.)
- Consulta unificada de la información asociada al usuario disponible en diferentes sistemas remotos
- Los resultados aparecerán en pantalla de forma parcial, actualizándose cada pocos segundos hasta mostrarse toda la información disponible
- Se informará al usuario si transcurrido un tiempo máximo de espera razonable (p. ej. 60 segs.) no ha sido posible recopilar toda la información, así como aquellos organismos de los cuales no ha sido posible obtenerla, para invitarle a reintentarlo posteriormente
- Consultas en paralelo a los diferentes backends
- Integración con éstos mediante una capa de conectores (patrón facade) que pueden efectuar varias invocaciones concurrentes (clientes multi-thread)
- Control de los tiempos máximos de espera (tanto timeouts individuales para invocar a cada backend como timeout global de la solicitud de un usuario)
- Polling desde el frontal web al business-core del sistema, para refrescar periódicamente la información mostrada al usuario acumulada hasta el momento
- Sin almacenamiento permanente de la información agregada:
- Cacheado (persistencia temporal mediante TTL) de respuestas parciales para su posterior agregación y retorno al solicitante (Apache Cassandra)
- Sistema basado en microservicios, mediante el uso de frameworks tipo Spring Cloud / Netflix OSS y explotación de sus capacidades:
- Descubrimiento (Eureka), balanceo de carga (Ribbon), inyección de configuración (Archaius), logs (Log4j), monitorización y alertas (ELK), seguridad en el acceso (Zuul), control de errores (Hystrix), etc.
- Sistema escalable horizontalmente. Utilización de componentes y herramientas distribuidas con capacidad nativa de escalado horizontal (p. ej. SpringBoot, Kafka), facilitando la utilización de infraestructura adicional a medida que crece la demanda o el número de backends integrados. Componentes independientes replicados para aumentar la disponibilidad y minimizar y acotar el impacto en situaciones de fallo o mal funcionamiento de los mismos
- Control de errores basado en la implementación del patrón circuit-breaker, minimizando la propagación y generación masiva de errores en caso de fallos puntuales de sistemas externos (backends de terceros)
- Minimizar la congestión del sistema en picos de demanda desacoplando sus componentes, p. ej. durante invocaciones masivas a backends lentos:
- Uso de colas de mensajes (patrón publish-subscribe) para controlar la congestión permitiendo la integración asíncrona entre algunos componentes del sistema (core y conectores)
- Agregación de logs, monitorización y alertas (log4j + ELK + Sentinel). Mecanismos de detección de degradación (health-check) y self-healing
- Posibilidad a futuro de desplegar el sistema en plataformas de gestión de contenedores (Docker swarm, Kubernetes, OpenShift)
- Compatibilidad con navegadores antiguos (p. ej. IE8) mediante una interfaz alternativa simplificada (uso del patrón backend-for-frontend para ofrecer diferentes implementaciones front en función de las capacidades del browser del cliente)
¡Llega el momento de pizarra y rotuladores de colores!
ARQUITECTURA LÓGICA
La arquitectura lógica del sistema es la siguiente:
- Conectores
- Message-broker (colas de mensajes)
- Componente hub (concentrador)
- Frontal web
La solución de mensajería para la integración asíncrona de componentes estará basada en Apache Kafka.
La solución de persistencia temporal para la gestión de solicitudes de usuario y cacheado de respuestas parciales por parte del componente hub estará basada en Apache Cassandra.
El frontal web será un aplicativo basado en Spring Web MVC, apoyándose en diferentes frameworks y tecnologías de presentación (p. ej. Angular, JQuery, AJAX, JSRS), pudiendo así ofrecer diferentes interfaces a diferentes navegadores (retro-compatibilidad mediante patrones backend-for-frontend).
Los componentes batch estarán basados en Spring Batch.
CONECTORES
La capa de conectores la componen diferentes módulos, independientes entre sí, uno por cada backend existente con el que integrarse. Cada conector debe implementar la correspondiente llamada al backend de un organismo, mediante el protocolo que corresponda.
El objetivo de esta capa es abstraer a otros componentes de las peculiaridades del acceso a cada backend de forma independiente:
- Diferentes protocolos, diferentes entornos y endpoints, uso de mocks, diferente protocolo de comunicación, configuraciones de seguridad y certificados, requerimientos de conectividad, control de errores y timeouts, circuit-breaker, etc.
Esta configuración debería poder ser inyectada en tiempo de despliegue o ejecución apoyándonos para ello en el componente correspondiente de la arquitectura de microservicios destinado a tal efecto (p. ej. Archaius)
Implementación de los conectores
Los conectores funcionarán en modo ‘batch’, y en cada iteración se realizarán las siguientes tareas:
- Consume un mensaje de la cola de peticiones (subscriber). Es decir, la recepción de un mensaje de la cola es el evento que dispara la ejecución.
- Analiza el mensaje y extrae la información que contiene:
- backend de destino, timestamp de la petición, TTL (time-to-live), payload con la información de negocio relevante para el backend (NIF/NIE, rango de fechas, etc.)
- Si el mensaje no va dirigido a este conector (par de colas request-response único compartido por todos los conectores) lo ignora. Fin de la iteración. En otro caso continúa la ejecución
- Si la antigüedad del mensaje supera el TTL (sysdate - timestamp > TTL):
- Construye un mensaje de KO por ‘timeout de la plataforma’ y lo publica en la cola de respuestas (publisher)
- Notifica este hecho y la información relevante mediante una traza de log de tipo ‘WARN’. Permitirá a la monitorización del sistema alertar de esta situación para diagnosticarla y corregirla
- Nota: esto significa que el sistema está congestionado, las peticiones son atendidas por los conectores demasiado tarde, cuando probablemente el peticionario ya ha disparado un timeout y no procesará la respuesta.
- Fin de la iteración. En otro caso continúa la ejecución
- Realiza una petición al backend correspondiente, enviando la información de negocio adecuada
- Recibe una respuesta del backend, la transforma y encapsula debidamente, y la publica en la cola de respuestas (publisher)
- En caso de error, construye un mensaje de KO por ‘error del backend’ y lo publica en la cola de respuestas
- Notifica este hecho y la información relevante mediante una traza de log de tipo ‘ERROR’. Permitirá a la monitorización del sistema alertar de esta situación para diagnosticarla y corregirla
- En caso de timeout, construye un mensaje de KO por ‘timeout del backend’ y lo publica en la cola de respuestas
- Notifica este hecho y la información relevante mediante una traza de log de tipo ‘ERROR’. Permitirá a la monitorización del sistema alertar de esta situación para diagnosticarla y corregirla
- Nota: esto significa que el backend no está funcionando debidamente y/o presenta tiempos de respuesta elevados, no entregando respuestas o haciéndolo demasiado tarde
- Tras cada paso de los anteriores, se volcará una traza de log de tipo ‘DEBUG’ incluyendo la información relevante, con el fin de facilitar la depuración de errores
- Se volcarán trazas de log de tipo ‘INFO’ tras cada evento relevante (consumo / publicación de un mensaje, invocación / respuesta de un backend, etc.) con fines de monitorización
Los valores de timeout también serán configurables de forma independiente para cada conector, lo que permitirá afinar la configuración en función de las capacidades de carga de cada backend.
Podrán desplegarse múltiples instancias de cada conector, con el fin de aumentar la disponibilidad y tolerancia a fallos. En este caso, la concurrencia de invocaciones al backend vendrá determinada por el nº de instancias y el nº de threads de ejecución en paralelo de cada una de ellas.
La implementación de un patrón circuit-breaker configurable (p. ej. mediante Hystrix) permitirá ‘abrir el circuito’ temporalmente cuando se detecten múltiples errores consecutivos en el acceso a un determinado backend. Esto minimizará la carga del sistema y la propagación de errores, evitando peticiones masivas a un backend que presenta problemas en un momento puntual. Con el circuito ‘abierto’, el conector devolverá mensajes de KO indicando este motivo. Se deben definir y configurar los criterios de ‘apertura’ y ‘cierre del circuito’ en cada caso.
Integración con el componente message-broker (Kafka)
Como consumidor de mensajes de la cola de peticiones (subscriber) cada conector se considera un ‘consumer group’, y cada instancia individual de un conector es considerado un miembro de dicho grupo.
El message-broker mantiene un puntero (offset) para cada consumer-group, indicando el siguiente mensaje a entregar. De forma que cada conector, en función del número de instancias en ejecución, rendimiento de cada backend, etc., pueda avanzar a su ritmo de forma independiente (p. ej. backends con diferentes capacidades de carga, tiempos de respuesta heterogéneos, throughput irregular)
Esto garantiza lo siguiente:
- Cada consumer-group recibirá todos y cada uno de los mensajes de la cola de peticiones, y en el orden en que fueron publicados (FIFO). Esto es:
- Cada conector recibe todas las peticiones pero descarta las que no le corresponden y atiende únicamente las que van dirigidas a él
- Cada instancia de un conector (miembro del grupo) recibirá (consumirá) el siguiente mensaje de la cola y el message-broker avanzará el puntero de todo el grupo, impidiendo que el mismo mensaje sea procesado por más de una instancia del mismo conector (evita el procesamiento múltiple del mismo mensaje e invocaciones repetidas a los backends)
- La incorporación de nuevos conectores al sistema (consumer-groups) no tiene impacto en la configuración del message-broker (inicializará nuevos offsets para ellos automáticamente)
- La incorporación de más instancias del mismo conector (más miembros al consumer-group) es también transparente para el message-broker
MESSAGE-BROKER
El componente message-broker, basado en Apache Kafka, es una solución escalable que permite integrar de forma asíncrona el hub (que es quien contiene la lógica del sistema) con la capa de conectores mediante el intercambio bidireccional de mensajes, actuando además como medida de contención ante la congestión del sistema durante el acceso masivo a los backends.
Éste se basa en el patrón publish-subscribe, y está inicialmente compuesto por un par único de colas (estructura FIFO) compartidas por todos los conectores:
- Cola de peticiones: es donde el hub (publisher) publica las diferentes peticiones a los backends, y de donde los conectores las obtienen (subscriber) para enviarlas a los mismos
- Cola de respuestas: es donde los conectores publican las respuestas de los backends (publisher), y de donde el hub las obtiene (subscriber) para componer la respuesta al frontal
No obstante, si el número de conectores crece notablemente, se definirá un criterio de agrupamiento de los mismos y se definirá un par dedicado de colas petición-respuesta para cada grupo de conectores. Esto permitirá reducir en cada conector el posible overhead resultante de preprocesar (y descartar) todos los mensajes que no van dirigidos al mismo.
HUB (CONCENTRADOR)
El componente hub o concentrador es el principal componente del core del sistema y alberga toda la lógica de negocio y control del mismo. Principalmente es el responsable de:
- Gestionar y registrar en caché las solicitudes entrantes desde el frontal web, así como sus marcas de tiempo (timestamps)
- Determinar y disparar las invocaciones a los diferentes backends a través de la capa de conectores (con la que se integra de forma asíncrona mediante el message-broker)
- Obtener y procesar las respuestas unitarias recibidas, y componer y actualizar la respuesta que se devolverá al frontal con toda la información agregada acumulada hasta el momento
- Controlar los errores recibidos de capas subyacentes, timeouts de backends y conectores, tiempos de espera del usuario (TTL de las solicitudes), etc.
- Realizar el purgado de la información en la caché temporal
- Custodiar el inventario de conectores y el resto de lógica de control (en base a requisitos concretos)
- API de servicios, compuesta por dos servicios principales:
- Nueva solicitud: es invocado por el componente front para cada nueva solicitud de información por parte de un usuario previamente identificado en el sistema:
- El componente front invoca a este servicio de forma síncrona por http, proporcionando como datos de entrada el identificador del usuario que inició sesión en el sistema (NIF/NIE) y otra información relevante a propagar hasta los backend durante las consultas unitarias (p. ej. rango de fechas, provincia… según requisitos)
- El servicio registra dicha solicitud en la caché asignándole como clave un identificador único (UUID) para recuperarla posteriormente, así como un timestamp
- El servicio devuelve como respuesta al invocador un “OK técnico” junto al UUID asociado. Presenta por tanto un funcionamiento de tipo “fire-and-forget”
- A continuación dispara la lógica de negocio (componente Core) relacionada con descomponer la nueva solicitud en peticiones unitarias a los diferentes backends, enviando el UUID de la solicitud original, su timestamp (que permite al conector descartar peticiones unitarias muy antiguas en situaciones de alta congestión del sistema), y el payload a propagar a los backends
- Actualizar resultados (cómo va lo mío): es invocado por el front de forma periódica, una vez que éste dispone del UUID asociado a una solicitud previa, y le permite obtener la información, parcial o totalmente actualizada, que se ha recopilado hasta el momento procedente de los diferentes backends / organismos:
- El componente front invoca a este servicio de forma síncrona por http, proporcionando como dato de entrada el UUID de una solicitud anterior (invocación previa al servicio de nueva petición)
- El servicio accede a la caché de solicitudes para obtener el estado actual de la solicitud indicada por el UUID. El estado de la solicitud reflejará qué backends han devuelto ya una respuesta de forma unitaria, cuáles no han respondido todavía, y si se ha detectado algún tipo de error durante alguna invocación a los mismos.
- Se construye un mensaje de respuesta para el frontal que incluirá la información recopilada hasta el momento, en función de la información de estado de la solicitud, acompañada de dos flags booleanos:
- ‘queryMore’, que indica (true) si la respuesta se considera provisional (por tanto es necesario que el frontal vuelva a pedir una nueva actualización más adelante, invocando a este mismo servicio), o si por el contrario (false) la respuesta se considera definitiva (por tanto no será necesario volver a invocar a este servicio)
- ‘complete’, que en función de las respuestas unitarias recibidas, del tiempo transcurrido (sysdate - timestamp) y de si se ha superado el umbral TTL definido como tiempo máximo de espera del frontal para obtener una respuesta definitiva, indica si la respuesta hasta el momento se puede considerar completa o incompleta, en cuyo caso se avisará al usuario de que no fue posible obtener toda la información solicitada a tiempo
- Core:
Para cada solicitud entrante, en función de la lógica de negocio implementada enviará a la capa de conectores los correspondientes mensajes a través del message-broker (publisher en la cola de peticiones) para su procesamiento.
- Batch de tratamiento de respuestas:
- Presenta un funcionamiento iterativo, escuchando eventos en la cola de respuestas (subscriber) del message-broker
- Si se despliegan varias instancias, todas deben formar parte del mismo consumer-group para evitar procesar la misma respuesta múltiples veces.
- Para cada respuesta recibida (que viene acompañada del UUID de la solicitud inicial y el identificador del conector correspondiente), actualiza en la caché el estado de la solicitud, añadiendo la información de respuesta procedente del backend, o en caso de que haya ocurrido un error, la información relativa a la causa del mismo (p. ej. error de backend / no disponible, no respondió a tiempo, etc.)
- Caché de solicitudes y respuestas:
- Batch de purgado de solicitudes antiguas (time-to-live):
Cada módulo dispondrá de su correspondiente logger para volcar información de depuración que posibilite su monitorización y facilite la trazabilidad de eventos en el sistema y el diagnóstico de problemas.
FRONTAL WEB
Por último tenemos el frontal web. Se trata de una aplicación web basada en Spring Web MVC que constituye la capa de presentación del sistema. Sus responsabilidades básicas son las siguientes:
- Implementa los mecanismos de autenticación y control de acceso de los usuarios al sistema, por diferentes vías (DNIe, Cl@ve, user/pass)
- Podrá disponer de varias interfaces de usuario a disposición de los diferentes navegadores web y dispositivos, con el fin de proporcionar retro-compatibilidad con los navegadores y dispositivos más antiguos. Para ello se apoyará en la adopción de patrones BFF (backend-for-frontend) y diferentes frameworks y tecnologías de presentación (p. ej. Angular, JQuery, AJAX, JSRS)
- Dispone de un adaptador API para el consumo de los servicios de negocio expuestos por los componentes Core del sistema (API del Hub) de forma controlada. Este componente asegurará que las solicitudes de información que se envían a la capa de negocio obtendrán información relativa únicamente al usuario autenticado en el frontal (posibles consideraciones de autorización mediante OAuth, resorce-owner, etc.)
- Login del usuario en el sistema
- Al acceder a la funcionalidad de consulta de expedientes hará uso del servicio ‘nueva solicitud’ de la capa de negocio del sistema
- Propagará el identificador del usuario previamente autenticado en el sistema (NIF/NIE), y el resto de información relevante a propagar hasta los backend (p. ej. rango de fechas, provincia, etc., según requisitos funcionales)
- Custodiará el identificador de solicitud UUID devuelto por el servicio de negocio
- Posteriormente invocará al servicio ‘actualizar resultados’ enviando el UUID de la solicitud obtenido en el paso anterior:
- El frontal continuará actualizando los resultados periódicamente y durante el tiempo estipulado (p. ej. cada 10 segundos durante 1 minuto) mediante invocaciones adicionales a este servicio mientras éste no le indique lo contrario (flag ‘queryMore’)
- Interpretará la respuesta del servicio, y mostrará los resultados obtenidos hasta el momento según la interfaz que se haya definido
- Indicará también si los resultados mostrados se consideran provisionales o definitivos (flag ‘queryMore’)
- En caso de mostrarse los resultados definitivos, se indicará además si éstos están o no completos (flag ‘complete’)
- En caso de mostrarse resultados incompletos se informará al usuario de aquellos posibles errores que hayan podido producirse:
- Error al obtener información concreta de determinados organismos
- Servicios no disponibles temporalmente
- Tiempo máximo de espera excedido
- Se invitará al usuario a repetir la solicitud más adelante, si procede
CONCLUSIONES
Como hemos visto, el uso de colas de mensajes permite desacoplar componentes del sistema y aprovechar las ventajas que ello conlleva. Esto no sale gratis, sino que introduce cierta complejidad y esfuerzo adicional que hay que abordar, pero para ciertos tipos de sistemas seguir este enfoque compensa con creces y permite dotarlos de una mayor robustez y tolerancia a fallos y picos de carga.
Una vez entregado este diseño no tuve más noticias al respecto, pero como tenía algo de tiempo disponible me propuse construir una pequeña prueba de concepto para comprobar qué tal podría llegar a funcionar. Y lo hice:
Pero eso os lo cuento otro día :)

Comentarios
Publicar un comentario